
AI Technology Review por: estudo aprofundado tem sido amplamente utilizado na segurança, financeiro, piloto automático e outros campos. A maioria dos programas no mercado são baseados em conjunto de instruções reduzido ou arquitetura RISC GPU, aumentando a capacidade de elevação da pluralidade de computação unidades de processamento.
cadeia de ferramentas recentemente, na rede de Lei Feng AI Yanxishe classe aberta, baseada em Ark Kun-Technology FAE Team Leader para explicar o programa e adaptar dados AI fluir arquitetura. Abrir classe reprodução de vídeo URL:
= Aitechtalkfangzhou
Compartilhar Palestrante:
Ark, líder da equipe de Kun-Technology FAE, é actualmente responsável pela plataforma de hardware Kun nuvem, plataforma de software e suporte do compilador. Ele é um análogo Mestre Imperial e design de chip digital, a bolsa IRC irlandês.
Compartilhar Tópico: aplicações baseadas em AI personalizados fluxos de dados
esboço Compartilhar:
A diferença entre os dados personalizados fluir arquitetura e conjunto de instruções arquitetura
Princípio do fluxo de dados arquitetura e desenvolvimento personalizado
dados personalizados fluir arquitetura método de desenvolvimento de aplicação rápida
Dados de aplicativos personalizados fluir arquitetura
Lei rede Feng AI Yanxishe para compartilhar conteúdo são resumidas como segue:
share de hoje está dividido em quatro partes:
A primeira parte, conversa sobre arquitetura de fluxo de dados personalizado é e o que é e qual é a arquitetura diferença conjunto de instruções.
O segundo introduz parte do princípio de fluxo de dados arquitetura e história básica de desenvolvimento personalizado.
A terceira parte descreve o desenvolvimento de métodos de fluxo de dados arquitetura para personalização rápido de aplicações, como a tecnologia cloud Kun para resolver o usuário final durante a utilização de uma arquitetura de alto desempenho personalizado, mas também para manter a simplicidade ea universalidade da aplicação pela cadeia de ferramentas.
A quarta parte descreve a aplicação e os fluxos de dados de projeto pouso reais arquitetura personalizados.

(AI explicar sobre a personalização de dados arquitetura de fluxo, por favor, olhar para trás, o vídeo em 0:02:10, http: //www.mooc.ai/open/course/588 = aitechtalkfangzhou?) Vamos olhar um conjunto de instruções clássico :
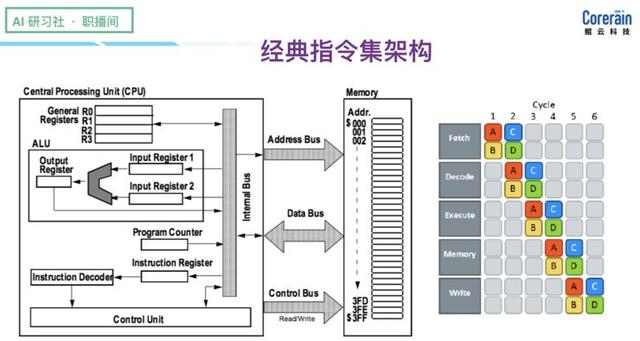
(Conjunto de instruções sobre esta explicação clássica, por favor, olhar para trás, o vídeo em 0:04:47, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou) Nós olhamos para um conjunto de instruções executadas exemplo disso é uma operação típica add.

(Execução conjunto de instruções sobre este caso para explicar, por favor, olhar para trás, o vídeo em 0:07:20, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou)
Os benefícios do conjunto de instruções clássico incluem:
Em primeiro lugar, agora a maior parte da arquitetura do conjunto de GPU, CPU instrução é baseado na camada de aplicação pelo software e editor de linguagem é convertida em linguagem de máquina, ou seja, o código binário, com operação muito alta eficiência na execução de instruções e para garantir que as vantagens da compatibilidade. Em segundo lugar, áreas específicas arquitetura dedicado, ferramentas de desenvolvimento pode ser usado para baixar uma arquitetura de aplicativo a fim de alcançar a computação eficiente. Em comparação com o conjunto de instruções, o fluxo de dados de núcleo é a de assegurar um cálculo eficaz por ciclo de relógio, os dados para garantir que não haveria sempre fluir para dentro da unidade de cálculo, para obter os dados de saída, os dados, eventualmente, é armazenada na memória, ou para Em seguida pipelining.

(Execução conjunto de instruções sobre este caso para explicar, por favor, olhar para trás, o vídeo em 0:10:20, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou)
Aqui é uma arquitetura de rede SSD com base neural típica:
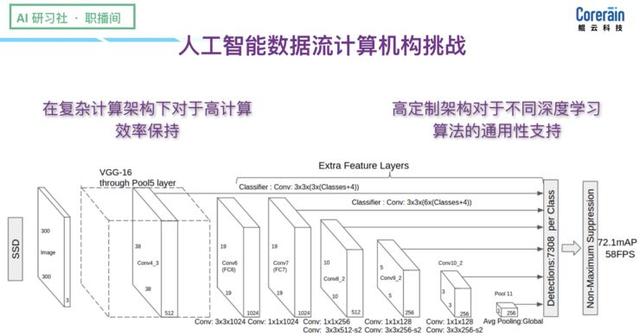
(Na parte da explicação, por favor, olhar para trás, o vídeo em 0:11:00, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou)
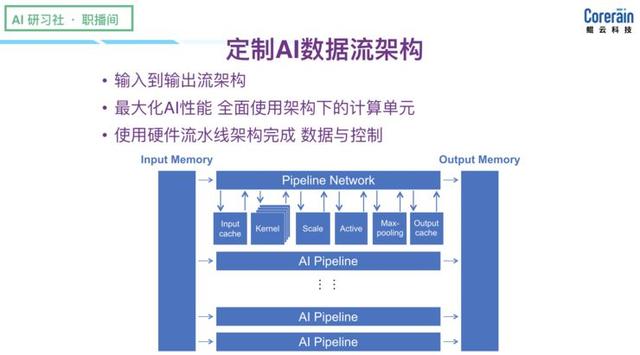
(On costume dados AI fluir arquitetura para explicar, por favor, olhar para trás, o vídeo em 0:17:50, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou) rapidamente perceber a detecção de rede neural, o primeiro é implementação subjacente paramétrico: passagem configurável. A figura vem do fundador de um artigo publicado em 1994, conta a história de como na arquitetura personalizado, as diferentes operações a realizar de uso geral algoritmos de inteligência artificial.
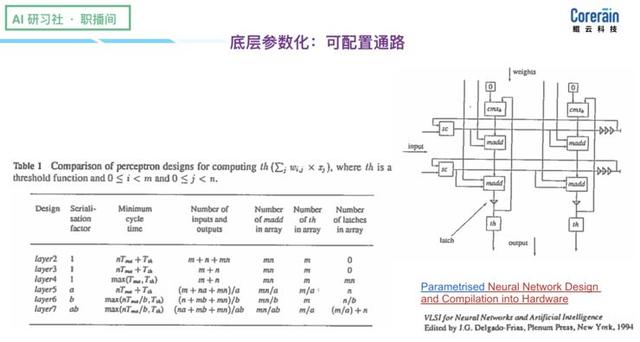
(Explique sobre a parametrização subjacente, por favor, olhar para trás, o vídeo em 0:24:15, http: //www.mooc.ai/open/course/588 = aitechtalkfangzhou?) A segunda é que várias camadas paralelas otimização escalável . Ao implementar o paralelismo de dados, filtro paralelo, canais paralelos, engine optimization Camada paralelo paralelo e o acelerador, para apoiar a computação de alto desempenho.

(Explicação na optimização paralelo escalável multi-camada, por favor olhar para trás para o vídeo 0:27:00, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou) Este é um exemplo de um conjunto de dados paralelos:
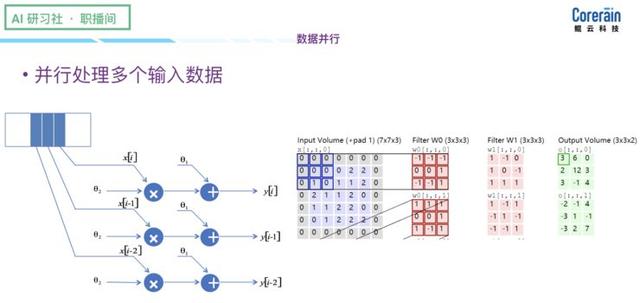
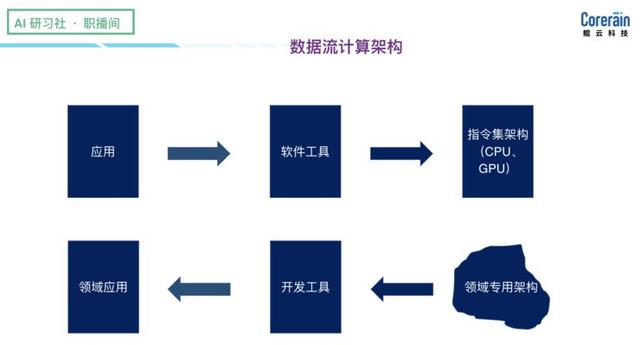
fluxo de dados baseado em uma arquitetura particular, pode não ser o conjunto de instruções universal é tão forte, que exige uma ferramenta a ser introduzida na estrutura da estrutura do algoritmo para concluir o processo de desconstrução de computação de rede neural, o seguinte é baseada em nossa estrutura da cadeia ferramenta feita AI --RainBuilder:

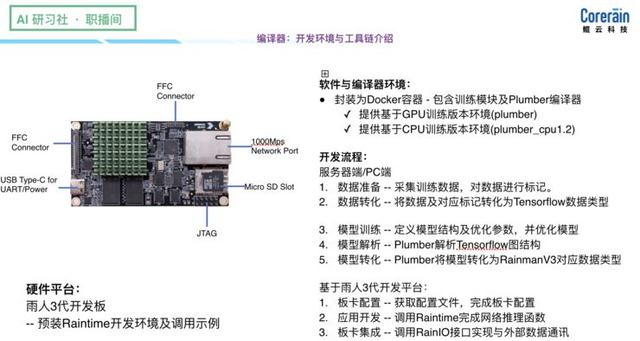
(Na descrição específica Rainbuilder, por favor, olhar para trás, o vídeo 0:31:55, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou)
Atualmente a direção de todo o programa arquitetura de fluxo de dados da nossa empresa inclui quatro áreas principais:
Robótica, veículos aéreos não tripulados e piloto automático
câmera
sensor
servidor

(Sobre as direções de aplicação de produto específico, por favor, olhar para trás, o vídeo em 0:35:45, http:? //Www.mooc.ai/open/course/588 = aitechtalkfangzhou)
Agora, Kun-Technology também recrutar todos os tipos de engenheiros, estamos ansiosos para participar!
Estes são os clientes atuais compartilham. Mais aberto de vídeo classe ir à rede Lei Feng AI Comunidade Yanxishe ( para assistir. Foco no número público micro-canal: AI Yanxishe (okweiwu), você pode obter o aviso de última classe aberta ao vivo tempo.
Clique para ler o texto, consulte praticantes AI deve estar ciente do conjunto de dados experimental