Autor: MA Xiao, análise de dados Zhejiang University of Finance e grandes dados de computação professor visitante. Depois de doutorado em matemática em 2006 na Universidade de Bremen, Alemanha, envolvidos na investigação e ensino em Dortmund Universidade Software Engineering Institute até 2011, veio a China.
Este artigo é um "programador" Subscribe "programador"
De grandes dados para dados rápida
Além da capacidade de analisar grandes conjuntos de dados em lote, moderno organização baseada em dados também precisa gerar insights a partir de dados recolhidos mais rapidamente possível e, eventualmente, tomar medidas. A este respeito, pilha convencional Hadoop (HDFS como uma camada de armazenamento, ou a Tez MapReduce como a moldura de processo, um gestor de recursos de cluster FIO) falta de gravidade. Para aliviar esta situação, a indústria tem sido propostos, tais como arquitetura Lambda (ver "programador" nov 2016 "Lambda e Kappa arquitetura de computação que eu vejo" um texto) e outras infra-estruturas. Na arquitectura Lambda, um "lento" de dados grande estrutura de processamento (por exemplo Hadoop pilha) combinada com um "rápido" fluir quadro do processo (por exemplo, Apache tempestade). Ou para retardar a moldura processo periodicamente reintegrados pelo rápido processamento de dados ou estrutura inteiramente descartado e substituído por os dados de quadro de processamento usando um processo lento. Claro, isso não é sem estrutura problemas Lambda-tipo, pode levar à duplicação de código e a necessidade de re-processamento e integração de dados.
SMACK Stack
SMACK é um chamado pilha tornaram-se populares na arquitectura ano passado. sabor de porções da pilha são as seguintes:
Faísca Como um general rápido, grande memória, o mecanismo de processamento de dados;
Mesos como um gestor de recursos de cluster;
Akka como um framework baseado em Scala que nos permite desenvolver tolerante a falhas, distribuídos, aplicativos simultâneos;
Cassandra como uma camada de armazenamento distribuído, de alta disponibilidade;
Kafka como uma distribuídos Message Broker / logs.
Primeiro vamos discutir os componentes rápidos SMACK stack, com atenção especial Cassandra, porque é diferente do resto da pilha, não parece amplamente utilizado no país.
Apache faísca
Apache faísca tornou-se um "sistema de dados grande." Os dados são carregados para o conjunto e armazenados na memória, e pode ser repetida consultas. Isso faz com que os algoritmos de aprendizagem de máquina faísca são particularmente eficazes. Desencadear um lote, streaming (modo de micro-lote), análise gráfica e tarefa aprendizado de máquina para fornecer uma interface unificada. Ele é escrito em Scala e expõe API Scala, Java, Python e R de. Além disso, o Spark pode executar consultas SQL nos dados, os analistas estão mais propício à aprendizagem ferramentas de BI tradicionais.
Apache Mesos
Apache mesos é uma fonte aberta aglomerado gerente, desenvolvido pela Universidade da Califórnia, Berkeley. Ele permite que o isolamento eficiente e compartilhamento de recursos entre aplicativos distribuídos. Em Mesos, uma tal aplicação distribuída é chamado uma moldura.
Akka
Akka quadro é construir programas simultâneos em execução na JVM. Enfatizar uma concorrência baseada no ator método: atores são tratados como primitivo, eles são apenas através de mensagens sem envolver a memória compartilhada para a comunicação. mensagem de resposta, os atores podem criar novos atores ou enviar outras mensagens. modelo ator preparado pela linguagem de programação Erlang, mais popular.
Apache Cassandra
Cassandra foi originalmente desenvolvido pelo Facebook, e mais tarde tornou-se um projeto de código aberto Apache. É, um sistema de arquivos distribuídos orientada a coluna NoSQL, semelhante ao Dynamo da Amazon e BigTable do Google. Em contraste com outros armazenamento de dados NoSQL, não dependem dos HDFS como o sistema de arquivos subjacente não tem arquitetura mestre, permitindo-lhe ter uma escalabilidade quase linear, e fácil de configurar e manter. Outra vantagem de Cassandra é para suportar a replicação centro transversal dados (XDCR). replicação de centro de dados realmente transversal ajuda a cargas de trabalho separados e análise de agrupamento. Cassandra Enterprise Edition está disponível a partir DataStax (
A chave de partição fixo, os dados são divididos em nó de cluster Cassandra. Sua arquitetura significa que ele não tem nenhum ponto único de falha. Segundo a CAP teorema, podemos ajustar a consistência e disponibilidade em uma base per-mesa.
Apache Kafka
SMACK na pilha, Kafka responsável pela transmissão do evento. aglomerado Kafka atua como a espinha dorsal mensagens SMACK pilha, as mensagens duplicadas em todo o cluster, e permanentemente salvos no disco para evitar perda de dados.
Antes da compreensão detalhada de como as várias partes da pilha SMACK trabalho juntos, vamos discutir a análise do modelo de dados Cassandra rápida e desafio enfrentado em Cassandra.
modelo de dados Cassandra
Como outros armazenamento de dados NoSQL, um sucesso de aplicações baseadas em Cassandra modelo de dados deve seguir o modo de "armazenamento de conteúdo sua consulta". Em outras palavras, ao contrário do banco de dados relacional, em um banco de dados relacional, que pode armazenar dados em um formulário padronizado. Quando falamos sobre o modelo de dados Cassandra, ainda usam a tabela de prazo, mas atua mais como uma espécie de mesa de Cassandra, um mapeamento distribuído, seguido por uma tabela de banco de dados relacional.
apoio Cassandra para a definição de tabelas e inserção de dados e linguagem de consulta SQL, chamado Cassandra Query Language (CQL).
Ao definir uma tabela Cassandra, é preciso fornecer uma chave de partição que determina como os dados são distribuídos entre os nós de cluster, assim como a forma de determinar a coluna do cluster para classificar os dados. Ao usar consultas CQL, só podemos consulta (cláusula WHERE) e classificado de acordo com as colunas em cluster.
Vejamos um exemplo de um documento Cassandra, o documento é serviços de compartilhamento de música lista modelados (como Spotify) são:

Neste exemplo, o UUID (ID universal original, entre uma pluralidade de máquinas para garantir único) chave ID de particionamento, song_order uma coluna de cluster, (id, song_order) necessidade de ser único em todas as linhas da tabela. Além disso, id a decisão sobre quais linhas de memória da máquina, song_order determinar a ordem de armazenamento das linhas no host físico. Também pode ser usado em uma chave de particionamento composto Cassandra, colocá-los em.
consulta CQL da seguinte forma:
Quaisquer aparece coluna na cláusula em que são necessárias para fazer parte da chave primária, ou pode ser definido no índice. Além disso, a chave de partição só pode ocorrer na operação de igualdade (=). Somente quando a linha selecionada é definido quando a consulta gama de hospedeiros é viável como um bloco contínuo de memória. Agrupando SQL-como colunas e cláusula LIMIT, CQL suporta ordenação, mas não têm uma função semelhante com GROUP BY.
De acordo com uma determinada coluna da consulta, reduzindo a necessidade de acesso ao disco aleatório, mas também fortemente limita o uso Cassandra como a análise do banco de dados. "A sua consulta de armazenamento de conteúdo" paradigma requer dados cuidadosas modelação baseada em consultas realizadas no banco de dados Cassandra, limitando assim a capacidade de suportar novas consultas. De modo a realizar os dados armazenados na análise Cassandra, deve ser carregado para um quadro de processamento de dados separados, que escolheu Apache quadro de faísca.

1 e FIG operação aglomerados com análises de agrupamento dos nós individuais justapostas de faísca
Faísca e ligação Cassandra
conector faísca-Cassandra (https://github.com/datastax/spark-cassandra-connector) pode tabela Cassandra como RDDS faísca, RDDS Cassandra tabela de gravação a faísca, e realizando qualquer aplicação faísca CQL consulta. Se também devem ser rastreados usando CQL cláusula WHERE pushdown para o nó do servidor.
De modo a maximizar o uso do ligador de dados posição Cassandra faísca de detecção de função de faísca e nodos Cassandra, o conjunto deve ser justaposta. A replicação XDCR Cassandra entre os centros de dados, na verdade, nos permite isolar uma análise de agrupamento, um nó Cassandra nó de faísca justapostos aglomerado Cassandra para uma operação de reescrever, os seus conteúdos são automaticamente copiado para a análise de agrupamento. Assim, quaisquer operações de análise graves não afetará o desempenho de gravação do conjunto Cassandra puro. A operação (de gravação pesada) e separação de cluster análise de agrupamento pode proporcionar os seguintes benefícios adicionais:
Dois aglomerados pode ser dimensionado de forma independente;
Uma vez que a operação da análise de agrupamento e com o modo de leitura / escrita diferente, cada cluster pode ser optimizada para alcançar o seu fim pretendido;
Cassandra processamento replicação automática de dados;
A única outra informação requerida (tais como uma tabela de pesquisa para ser ligado à mesma) é armazenado na análise de agrupamento.
arquitetura mesos
Mesos projetados a partir do zero para manipulação de exceção carga de trabalho complexo, isto é os trabalhos em lotes de longa execução e o tipo de tarefas de processamento de eventos pode ser uma combinação de curto juntos. Mesos cluster consiste em dois tipos de nós:
O nó mestre é responsável por fornecer os recursos e programação;
A partir do nó, executando a tarefa real.
O nó mestre pode ser duplicado para proporcionar uma elevada disponibilidade. Neste caso, Zookeeper pode ser usado para as eleições de liderança e descoberta de serviços. processo de missão Use Mesos, siga estes passos:
Liberar os recursos disponíveis para o nó mestre do nó;
O nodo principal transmite o recurso à armação (App);
Scheduler tarefas quadro resposta precisam ser agendadas;
Missão enviada pelo mestre ao escravo.
Usamos duas ferramentas para ajudar a planejar trabalho Mesos: objetivos maratona para agendar uma tarefa por um longo tempo para executar; Chronos age como um "cron distribuída", repetiu tarefas de curto execução. Podemos implantar / cluster faísca Mesos / Cassandra das seguintes formas:
Mesos nó mestre e o nó Zookeeper justapostos;
Faísca actuador Cassandra nó nó justaposta.
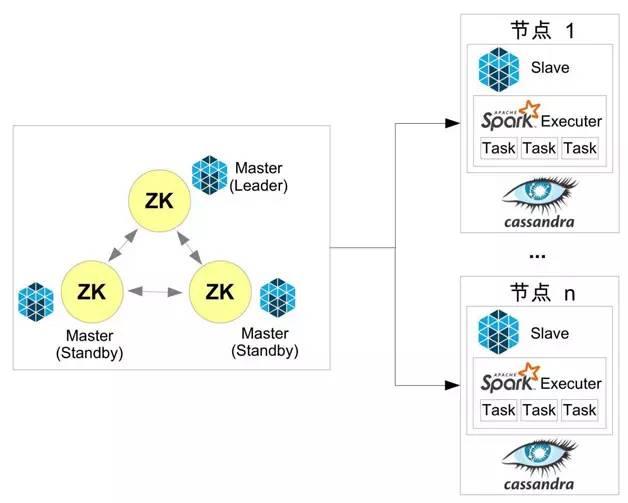
E A Fig. 2 Cassandra implantação de faísca de Mesos
Akka usando dados tomados
Depois de selecionar o nível de armazenamento apropriado, e agora precisa decidir como lidar com os dados recebidos. Captação camada requisitos de dados é:
Baixa latência e alto rendimento
elasticidade
escalabilidade
Contrapressão lidar com o pico de carga
Os três primeiros satisfazer plenamente o ator, como o processamento de cada evento de entrada a partir de uma solicitação HTTP e armazena no Cassandra.
Kafka pré-tratamento com
Uma desvantagem do projeto é apátrida Akka: ator não pode executar qualquer pré-processamento de dados. Cassandra também não é adequado. Faísca de ignição Streaming de utilização ou a aplicação de tais pré-polimerização não é ideal, porque faísca streaming arquitectura micro-lote não é adequado para o tratamento de eventos rápido.
Apache Kafka é uma alternativa apropriada. Portanto SMACK pilha, log actores Akka distribuído escreve os dados pré-processados, tais como Apache Kafka. Para ler dados de Kafka, pode confiar faísca Streaming, faísca Transmissão usado para fazer backup de dados armazenados no HDFS ou objeto (por exemplo, a OSS Ali nuvem ou Amazon S3), enquanto ele grava conjunto Cassandra. Este efectivamente actua como um mecanismo de cópia de segurança, e em conformidade com a forma de realização, o custo de armazenamento de OSS / S3 pode ser muito menor do que os dados retidos no agrupamento Kafka. Ele pode ser restaurado usando os dados da faísca armazenamento de objetos. África Central no armazenamento local de dados armazenar objeto também impede que qualquer centro de classe de dados falha grave impacto sobre os dados da organização.
conclusão
SMACK pilha tem as seguintes vantagens:
caixa de ferramentas simples suporta uma variedade de tarefas de processamento de dados (fluxo, em lote, tipo Lambda da arquitectura);
Baseando-se no quadro de código aberto testada;
Unified gestão aglomerado;
Fácil de ampliar e replicar.
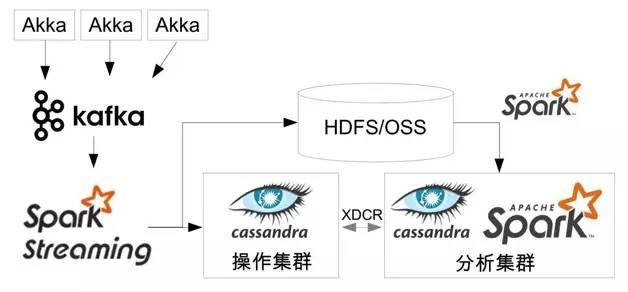
Figura 3 SMACK Stack Visão Geral da Arquitetura
Além disso, o código específico principais componentes de aplicação (Akka, Kafka, Centelha) deve ser escrito usando Scala pode ser programado de forma a permitir o compartilhamento eficiente de tipos de código de lógica de negócios em diferentes partes da arquitetura.