
Fonte: Almost Human
Este artigo sobre 2450 Word, leitura recomendada 5 minutos.
Este artigo é introduzir o método pode melhorar a equipe de tomada de decisão pela Liga da tecnologia AI Inteligência Artificial.

O projeto consiste em três partes, Destinado a MOBA jogo "Heroes União" batalha é modelada como um processo de decisão Markov, e em seguida, aplicar as melhores decisões para fortalecer o estudo, a decisão também leva em conta as preferências do jogador, e além da simples estatísticas "painel de avaliação".
Autor enviados a cada parte do modelo em Kaggle modo que compreendemos melhor a estrutura de processos e dados do modelo:
A primeira parte:
https://www.kaggle.com/osbornep/lol-ai-model-part-1-initial-eda-and-first-mdp
Parte II:
https://www.kaggle.com/osbornep/lol-ai-model-part-2-redesign-mdp-with-gold-diff
Parte III:
https://www.kaggle.com/osbornep/lol-ai-model-part-3-final-output
Atualmente, o projeto ainda está em andamento, esperamos mostrar a aprendizagem de máquina sofisticada que você pode fazer no jogo. Placar do jogo não é simplesmente estatísticas "painel de avaliação", como mostrado abaixo:

Motivação e objetivos
League of Legends é um jogo de vídeo esportes de equipe, cada jogo tem duas equipes (cinco pessoas por equipe), são concorrentes para fazer soldados de homicídio. Ganhar uma vantagem se tornará mais poderoso do que os jogadores adversários (melhor equipamento, atualizações mais rápidas), uma das vantagens continuam a aumentar, as chances de ganhar também aumenta. Portanto, o jogo de acompanhamento para jogar e jogar e lutar antes dependem, e, finalmente, do outro lado vai destruir a base para ganhar o jogo.
De acordo com a situação como essa modelagem antecedente não é nova; Ao longo dos anos, os investigadores têm vindo a considerar como aplicar este método em esportes como basquete (https://arxiv.org/pdf/1507.01816.pdf), em esses movimentos, passe, drible, falta causar uma série de ações ou perder uma pontuação. Tais estudos são destinados a fornecer informações mais detalhadas do que as estatísticas de pontuação simples (jogador de basquete ou um jogo onde os jogadores começam a marcar a cabeça), e considerando o tempo quando modelada como uma série contínua de eventos, a equipe deve ser a forma de operar.
Desta forma, a modelagem é mais jogos importantes, como League of Legends, porque neste tipo de jogo, os jogadores e arrepios pode começar após os assassinatos e atualização de equipamentos. Por exemplo, um jogador pode obter a primeira morte para obter moedas extra para comprar mais equipamentos. E depois com o equipamento, o jogador torna-se mais poderoso e em seguida, obter mais cabeça, e assim por diante, até que ele levou a equipe a obter a vitória final. Esta liderança é chamado de "bola de neve", porque os jogadores vão continuar a acumular vantagem, mas uma grande parte do tempo, a equipe que o jogador está em jogo não é necessariamente os prevalecentes partido, arrepios e trabalho em equipe é mais importante.
O objetivo do projeto é simples: podemos calcular a próxima melhor jogo de acordo com o antecedente jogo, então aumentar o jogo final da vencedora com base em dados reais.
No entanto, os fatores que afetam um jogo os jogadores têm um monte de tomada de decisão, não é tão fácil de prever. Não importa o quanto os dados são recolhidos, a quantidade de informação obtida é sempre o jogador mais do que qualquer computador (pelo menos por enquanto!). Por exemplo, em um jogo, o jogador pode exceder o nível de jogo ou louco jogo, ou a preferência por um determinado estilo de jogo (geralmente definido em termos de sua escolha de heróis). Alguns jogadores vão naturalmente se tornam mais agressivos, como matar, alguns jogadores são mais desenvolvimento passiva tem sido até soldados. Por isso, desenvolvemos ainda mais o modelo, permitindo aos jogadores jogar de acordo com as suas preferências de ajuste sugeridas.
Vamos modelo de "inteligência artificial"
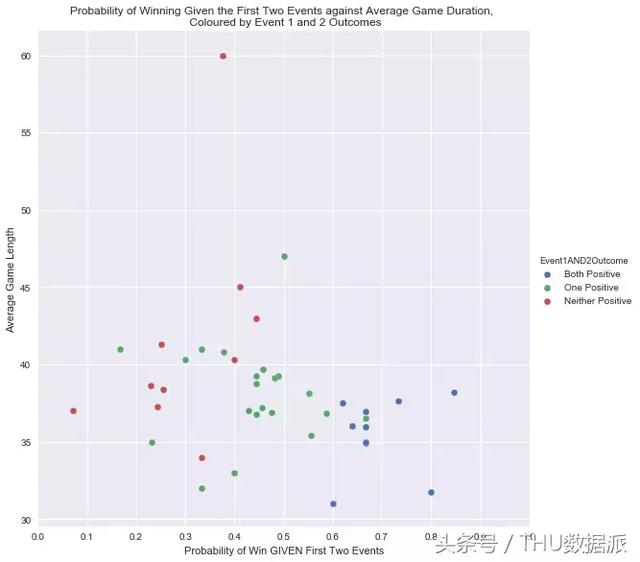
Na primeira parte, temos feito alguns introdutório análise estatística. Por exemplo, assume-se nas equipas de jogo até a primeira e segunda soldado, podemos calcular a probabilidade de ganhar, como mostrado na FIG.
Há dois componentes para fazer o nosso projeto de ir além das estatísticas simples de Inteligência Artificial:
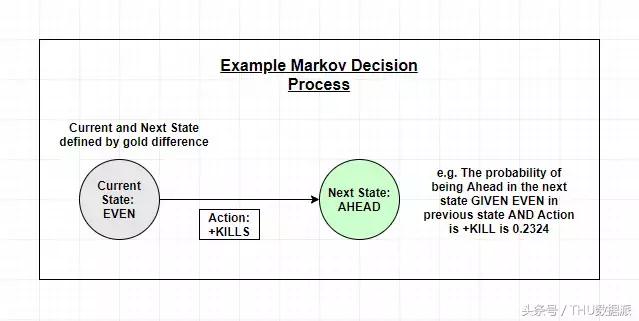
Nós definimos Markov processos de decisão ea forma de preferências dos usuários coletar irá determinar a aprendizagem modelo de conteúdo e de saída.
Pré-tratamento e criação de Markov Processo de decisão de acordo para combinar as estatísticas.
AI Modelo II: dinheiro para combater a introdução de eficiência
Percebi a partir dos resultados do primeiro modelo, nós não consideramos o negativo e eventos positivos podem produzir um efeito cumulativo sobre o futuro. Em outras palavras, antes ou depois do ponto de tempo de tempo, o MDP atual (Processo de Decisão de Markov) probabilidade pode acontecer. No jogo, isso não é verdade. Uma vez atrás, matar, tomar as torres, arrasta-se tornará mais difícil, precisamos levar isso em conta. Então, nós temos o dinheiro para lutar contra a introdução de eficiência entre a equipe de redefinir o estado. A meta atual é estabelecer uma definição do estatuto do MDP, o estado pode ser seqüência de eventos, ou se a equipe por trás ou pela frente. Nós será a diferença entre o ouro nas seguintes categorias:
Nós também precisamos considerar a situação sem incidentes, e para ser classificado como um "não" do evento, a fim de garantir que cada minuto de cada evento. O "não" evento indica que uma decisão da equipe para atrasar o jogo, para os mais hábeis no início do jogo para obter equipe de ouro distinguir, sem a necessidade de matar (ou pelo soldado morto)-los. No entanto, isso vai aumentar muito a quantidade de dados. Porque nós combinamos os jogos disponíveis adicionou sete categorias, mas se temos acesso a jogo mais convencional, então a quantidade de dados suficientes. Como mencionado anteriormente, que pode ser resumida pelas seguintes etapas:
O pré-tratamento
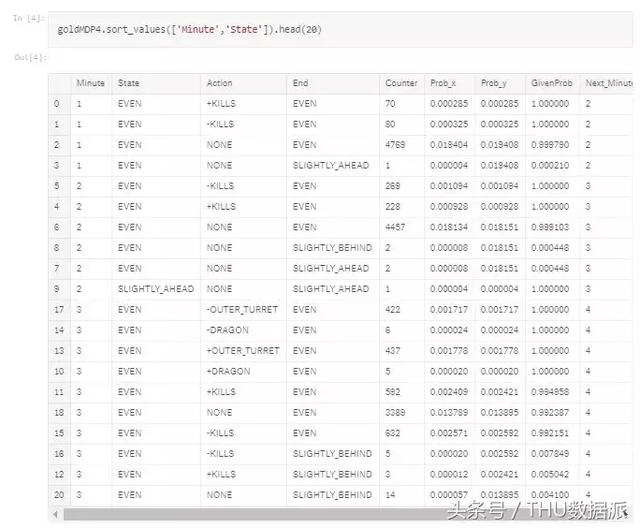
saída de Markov processo de decisão
Usando um modelo simples Código V6
Nossa versão final do modelo é brevemente resumida da seguinte forma:
A introdução de preferências de recompensa
Em primeiro lugar, ajustar o código do modelo, o bônus incluídos nos cálculos de retorno. Então, quando executar o modelo, introduzido para certos atos de preconceito, ao invés de simplesmente a recompensa igual a zero.
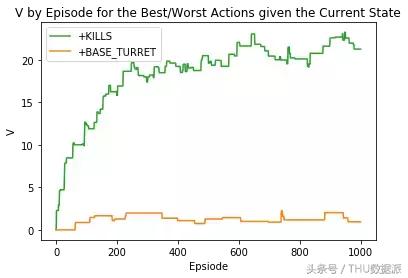
Se nós fizemos comentários positivos sobre a ação "+ MATA" output
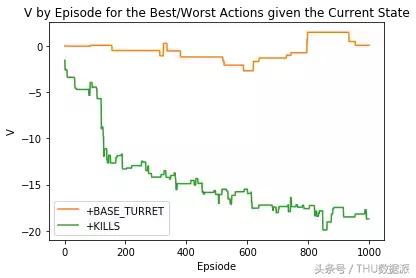
Se avaliarmos as ações negativas "+ MATA" output
Mais preferências reais do jogador
Agora podemos tentar aproximar verdadeiras preferências do jogador. Neste caso, nós randomizados para permitir algum incentivo para cumprir as seguintes regras:
Portanto, estamos todos na cabeça e o valor mínimo de -0.05 rasteja incentivos, recompensas e outras ações são gerados aleatoriamente entre -0,05 e 0,05.
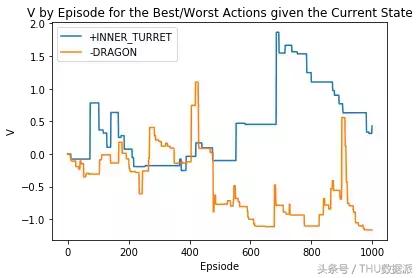
saída randomizado após a adjudicação do jogador
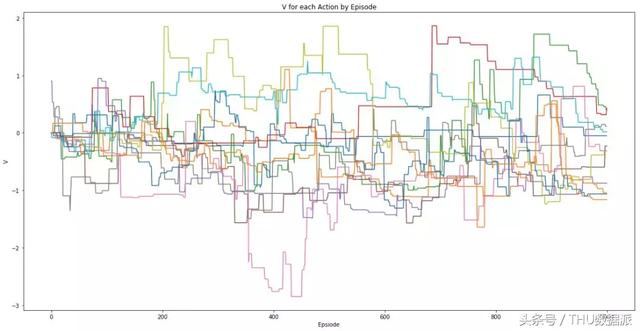
Saída após os jogadores randomização recompensa de todas as ações obtidos
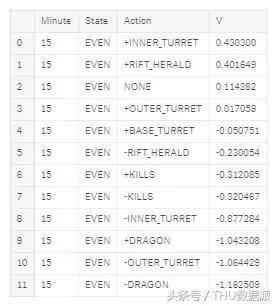
resultado final, dado o valor da diferença de estado de exibição atual entre o ouro e o funcionamento de cada minuto
Resumo e feedback sobre os prêmios jogador
I simplificado algumas características (tais como "mata", de fato, o número não é representativo da cabeça), os dados são pouco provável para representar um jogo normal. No entanto, espero que este artigo mostram claramente um conceito interessante, para incentivar mais pessoas para discutir a direção futura da área.
Primeiro, eu vou conseguir melhorias significativas precisam ser feitas antes da lista:
Nós introduzimos a saída do modelo e do impacto de uma recompensa, mas como para obter a recompensa? Podemos considerar vários métodos, mas com base na minha pesquisa anterior, acho que a melhor maneira é considerar tanto uma ação individual qualidade envolve tendo em conta a qualidade de troca de recompensa.
Isto torna-se cada vez mais complexa, não vou revelar neste artigo, mas em poucas palavras, queremos que os jogadores para coincidir com a decisão, que a próxima melhor decisão depende atualizações. Por exemplo, se uma equipe de jogadores entre si eliminados, eles podem ficar grande dragão. Nosso modelo terá uma probabilidade da sequência de eventos em conta, portanto, devemos pensar sobre a decisão do jogador da mesma maneira. Essa idéia veio de um papel de "DJ-MC: A Reforço-Learning Agent for Music Playlist recomendação", o documento ilustra como o feedback mapeados de forma mais pormenorizada.
métodos de feedback de coleta pode determinar o quão bem sucedido nosso modelo. A meu ver, o objetivo final é fazer o nosso melhor para fornecer em tempo real tomada de decisão sugestões para o próximo jogador. Desta forma, os jogadores serão capazes de escolher entre vários melhores decisões (classificada de caso win) dados calculados de acordo com o jogo. Você pode acompanhar a escolha do jogador em vários jogos, a mais conhecimento e compreensão das preferências do jogador. Isto também significa que podemos controlar não só o resultado da decisão, mas também previu intenções do jogador (por exemplo, as tentativas do jogador para desmontar a torre apenas para ser morto), e até mesmo para fornecer informações para uma análise mais avançada.
É claro, esses pensamentos podem causar membros da equipe discrepâncias opiniões, ele pode tornar o jogo menos emocionante. Mas eu acho que essa idéia pode ser convencional ou baixa benefício jogadores de nível, porque este nível de jogadores para comunicar as decisões de jogo claramente difíceis. Isso também pode ajudar a identificar "câncer", os jogadores, porque a equipe esperar consenso por sistema de votação, então você pode ver o "câncer" de jogadores nem sempre é acompanhar a equipe não pretende ignorar seus companheiros.
Recomendar votar exemplo modelo de sistema de ambiente de jogo em tempo real
link original:
https://towardsdatascience.com/ai-in-video-games-improving-decision-making-in-league-of-legends-using-real-match-statistics-and-29ebc149b0d0