Este artigo irá explicar o conceito de rede neural convolutional (CNN) através de uma série de imagem da cisne, e usar as imagens de processamento da CNN em uma Multilayer Perceptron Rede Neural convencional.

Suponha que nós queremos criar um modelo de rede neural capaz de identificar a imagem de um cisne.
Swan têm certas características, ele pode ser usado para ajudar a determinar se a presença na cisne imagem, de pescoço comprido, por exemplo, branco e similares.

Swan ter certas características pode ser usado para fins de identificação
Para algumas imagens, pode ser difícil determinar se existe um cisne, olhar para a imagem seguinte.

Difícil distinguir imagem Cisne
Esses recursos ainda estão presentes na imagem acima, mas são difíceis de encontrar características definidas acima. Além disso, haverá alguns dos casos mais extremos.

casos Swan extremas classificados
Pelo menos a cor é o mesmo, certo? Ou ......

Não se esqueça esses cisnes negros.
A situação pode ser pior? Absolutamente.

pior caso
Ok, agora que temos o suficiente foto cisne.
Vamos falar sobre a rede neural.
Agora, nós, basicamente, ter sido de uma forma muito ingênuo de falar sobre os recursos detectados na imagem. Os pesquisadores construíram uma variedade de tecnologia de visão computacional para resolver estas questões: SIFT, RÁPIDO, SURF, breve e assim por diante. No entanto, houve um problema semelhante: o detector demasiado geral ou demasiado do design, o que os torna muito fácil ou difícil generalizar.
Se aprendermos a função de detecção, como fazer?
· Precisamos de um estudo pode ser caracterizada (ou recurso de aprendizagem) do sistema.
Aprender é uma caracterização permite que o sistema automaticamente encontrar dada a tarefa de recursos relacionados à tecnologia. Substitua obras função manual. Há várias dicas:
· Não supervisionada (K-means, APC, ......)
· Supervisão (Sup. Dicionário de aprendizagem, redes neurais!)
Supondo que você já está familiarizado com a rede neural tradicional é chamada Multilayer Perceptron (MLP) é. Se você não estiver familiarizado com o conteúdo, em seguida, recebe centenas de tutoriais sobre MLP trabalho na rede. Estes são modelados no cérebro humano, em que os nodos ligados por uma estimulação neuronal, e é activado apenas quando um determinado limiar.

perceptron multicamadas padrão (redes neurais tradicionais)
MLP tem vários inconvenientes, em particular no processamento de imagem. MLP utiliza um perceptron (por exemplo, os pixels da imagem, multiplicado por 3, no caso de RGB), para cada entrada. Para imagens grandes, o peso certo rapidamente tornar-se pesado. Para 224 x 224 pixel da imagem ter três canais de cor, deve ser treinado por peso de aproximadamente 150.000! Como resultado, as dificuldades na formação e overfitting.
Outro problema comum é a resposta MLP diferente de entrada (imagem) para e versão mudou - eles não são translação invariante. Por exemplo, se a imagem do gato aparece no canto superior esquerdo no canto inferior direito de uma imagem e outra foto, o MLP vai tentar corrigir a si mesmo e acredita que o gato sempre aparecerá nesta parte da imagem.
Obviamente, MLP não é a melhor idéia para processamento de imagem. Um grande problema é que quando a imagem é achatada como MLP, informação espacial está perdido. Nós perto do muito importantes porque ajudam a definir as características da imagem.
Portanto, precisamos de uma maneira de tirar proveito dos recursos de imagem espacial (pixels) de relevância, para que possamos ver a imagem do gato, não importa onde ele aparece. Na figura abaixo, estamos aprendendo a redundância. Este método não é perfeito, porque o gato pode aparecer em outro local.

Agora vamos passar para a CNN como resolver a maioria dos problemas.

CNN aproveita pixels próximas e de pixel distância fatos mais relevantes
Usando algo chamado um filtro, analisamos a influência de pixels próximos. Usando o filtro de tamanho especificado (regra de ouro é um 3x3 ou 5x5), então o filtro é movido a partir do canto inferior direito da imagem. Para cada ponto da imagem, baseado no filtro de convolução Cale.
Filtros podem estar relacionadas a qualquer coisa, para a fotografia humana, um filtro pode ser associado a ver o nariz, e nosso filtro nariz vai deixar-nos ver a força do nariz aparecem na imagem, e quantos e em que ocorrem localização. Em comparação com MLP, o que reduz o número de rede neural deve aprender os pesos, e também significa que quando a localização desses recursos for alterado, ele não vai abandonar a rede neural.
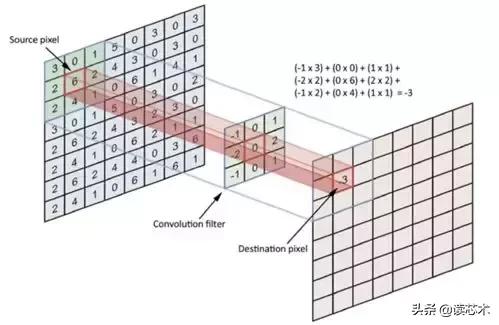
operação de convolução
Se você quiser saber como aprender através da rede de diferentes funções, e se a rede pode aprender a mesma funcionalidade (10 filtro irá dirigir um redundante bit), isso basicamente não ocorre. Ao construir a rede, nós aleatoriamente designados valor do filtro, e em seguida, continuamente atualizado durante o treinamento da rede. A menos que o número do filtro selecionado é extremamente grande, caso contrário, a possibilidade de dois filtros idênticos são muito pequenos.
O exemplo seguinte é dado ou referido núcleo do filtro.

Exemplos de filtros de CNN núcleo
Depois que a imagem é mapeado sobre o filtro para gerar um recurso de cada filtro. Em seguida, através da função de activação para obter estas funções, a função de activação determina a posição da imagem, dada a existência de uma característica. Então, podemos fazer muitas coisas, como adicionar mais camadas e filtros para criar mais mapeamento recurso. Como nós criamos mais aprofundada CNN, esses mapas se tornou cada vez mais abstrata. Também pode usar o conjunto de camadas seleccionadas para um valor máximo sobre os elementos da figura, e usá-los como entrada para uma camada subsequente. Em teoria, qualquer tipo de operações pode ser feito na camada de pooling, mas, na verdade, apenas o maior piscina porque queremos encontrar os valores extremos - que é a nossa rede para ver quando esta função!

Exemplo CNN convolução que tem duas camadas, dois classificação final de um camada combinada e uma totalmente ligado, que é determinada como a imagem de uma de várias categorias.
Só para reiterar o que descobrimos até agora. Sabemos MLP:
Não dimensionar bem image
Ignorar a informação de localização de pixel associado com o vizinho e trouxe
Eu não posso lidar com tradução
CNN pensamento geral é a propriedade de forma inteligente se adaptar à imagem:
bairro localização de pixel ter significado semântico e
· Elementos de interesse podem aparecer em qualquer posição da imagem

MLP arquitetura e CNN comparar
CNN também é composto de uma camada, mas as camadas não são completamente ligado a: eles têm filtros, em forma de cubo conjunto certo peso de aplicação em toda a imagem. Cada filtro é referida como um núcleo fatia 2D. Estes filtros e introduziu partilha de parâmetros invariância translacional. Como eles são aplicados? É a convolução é claro!

Este exemplo mostra como usar o filtro do kernel de convolução aplicado à imagem
Agora há uma pergunta: O que aconteceria bordas da imagem? Se aplicarmos a convolução na imagem normal, o resultado da amostragem realizada de acordo com o tamanho do filtro. Se não queremos que isso aconteça, como fazer? Você pode usar o estofamento.

Esta figura mostra como preencher completamente preenchido eo mesmo se aplica a CNN
Caracterizado pelo facto do núcleo de filtro gerado pelo mapeamento do mesmo tamanho que a imagem original sobre a natureza de enchimento. Isso é útil para a profundidade CNN, porque nós não queremos reduzir a produção, para o qual temos apenas à esquerda uma rede de área 2x2 para prever o resultado final.
Se tivermos muitos diagrama funcional, então como esses recursos se combinam para nos ajudar a alcançar o resultado final na rede?

Deve ficar claro que, cada filtro são convolved com a entrada inteira cubo 3D, mas irá gerar elementos do mapa em 2D.
· Porque nós temos vários filtros, para acabar com uma saída 3D: Cada filtro possui um mapa em 2D
· Tamanho característica textura pode variar amplamente de uma camada para a próxima convolução: uma entrada de 32x32x16 camada de entrada, se a camada de filtro 128, uma saída 32x32x128 saída.
Use convolução o filtro de imagem para gerar um diagrama característico que mostra as características presentes na imagem é realçada FIG elemento dado.
camada de convolução, que, basicamente, utilizar uma pluralidade de filtros em uma imagem para extrair várias características. Mas o mais importante, estamos aprendendo esses filtros! Estamos faltando uma coisa: não-linear.
retificador não-linear de maior sucesso da CNN é uma função linear (Relu), pode resolver o problema desaparecer gradiente ocorrendo em sigmoids. Relu mais fácil de calcular e gerar dispersão (nem sempre benéfica).
rede neural convolucional com uma camada de três tipos: uma camada de convolução, e a camada de células camada completamente ligada. Estas camadas de cada camada tendo diferentes parâmetros podem ser optimizados, e executa diversas funções sobre os dados de entrada.

camada convolução caracterizado
camada de filtro de convolução é aplicada aos mapas de imagem originais ou outros elementos das camadas profundas da CNN. Isto é onde a maioria dos parâmetros especificados pelo usuário na rede. O parâmetro mais importante é o tamanho do número de núcleos e núcleos.
camada reunida caracterizado
camada celular semelhante à camada de convolução, mas que desempenham uma função específica, tal como células máxima, que tem um valor máximo numa região específica do filtro, ou a célula média que calcula a média da área do filtro. Estes são geralmente utilizados para reduzir a dimensão da rede.
camada de ligação totalmente funcional
A camada está totalmente ligada a CNN colocado antes da saída de classificação, e para o nivelamento antes de os resultados da classificação. Isto é semelhante à camada de um MLP saída.
arquitetura padrão da CNN
Cada camada CNN estão aprendendo mais e filtros mais complexos.
· A primeira camada é substancialmente aprendizagem recurso de detecção de Filtro: arestas, cantos, etc.
· Filtro Aprendizagem detecta a porção de camada intermédia do objecto. Para o rosto, eles podem aprender a reagir ao olhos, nariz, etc.
* Indica uma camada final mais elevado: completar a sua identificação aprendizagem de objectos de diferentes formas e posições.

Exemplos CNN treinados para reconhecer objetos específicos e o mapa recurso gerado
