rede de Lei Feng: Este artigo foi originalmente intitulado Reforço aprendizagem com TensorFlow, de autoria de Justin Francis, legendas de texto compilados pelo grupo de Lei Feng.
Tradução / Lin Lihong Wen Cato
Revisão / Julia
Acabamento / Jiang Fan
A profundidade do aprendizado por reforço (Ou melhorar a aprendizagem) é uma área que um difícil de dominar. Entre uma grande variedade de termos e abreviaturas modelo de aprendizagem, sempre ainda difícil de encontrar a melhor maneira de resolver o problema de aprendizado por reforço. Reforço teoria da aprendizagem não é só recentemente surgiram. Na verdade, parte da teoria de aprendizagem reforço pode ser rastreada até meados dos anos 1950. Se você é um novato para fortalecer a aprendizagem pura, eu sugiro que você olhar para o meu artigo anterior "aprendizagem Introdução reforço e OpenAI Gym" para fortalecer a aprender as noções básicas de aprendizagem.
Profundidade reforço gradiente aprendendo muito precisa ser atualizado. Algumas ferramentas de aprendizagem profundas, tais como TensorFlow particularmente útil quando cálculo destes gradientes. reforço visual profundidade aprendendo também obriga os Estados a mostrar mais abstrato, a este respeito, a melhor rede neural realizar convolução. rede de Lei Feng Nesta tradução, nós estaremos usando Python, TensorFlow e aprendizado por reforço para resolver a biblioteca jogo Gym 3D Doom ( "Perdição") em kits médicos ambiente coletados, você deseja obter a versão completa do código e a necessidade de instalar dependências Por favor, visite nosso repositório GitHub e este artigo Jupyter Notebook.
sonda ambiental
Neste ambiente, os jogadores vão jogar um homem que está na água corrosiva, precisamos encontrar uma maneira de coletar kits médicos e seguro para sair.
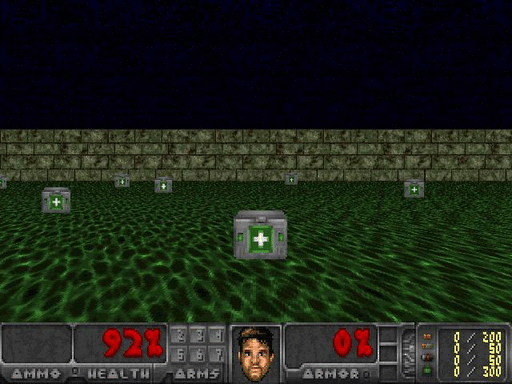
1. A FIG ambiente, Justin Francis fornecida
Um método de aprendizado por reforço podemos resolver este problema é - combinação de referência do algoritmo de aprendizado por reforço. Isso vai reforçar o ponto simples, ele só precisa vir do status atual e premia os dados de comportamento ambiental. Também descrita como um reforço método de gradiente de política Porque só é avaliado e atualizado a estratégia Agent. estratégia inteligente é entender o estado atual do comportamento mostrado. Por exemplo, em um pong jogo (semelhante ao ténis de mesa), uma estratégia é simples: Se a bola se move em um determinado ângulo, a melhor corresponde comportamento a este ponto da barreira. Além da rede neural convolução para avaliar a melhor estratégia em um determinado estado, nós também usou a mesma rede para avaliar o valor de um determinado estado ou prever incentivos de longo prazo com base em.
Primeiro, vamos definir o nosso ambiente com Gym
Antes de deixar estudo Agent, nós encontramos este é um agente de referência observação selecionados aleatoriamente, o lugar é muito claro que ainda temos muito a aprender.
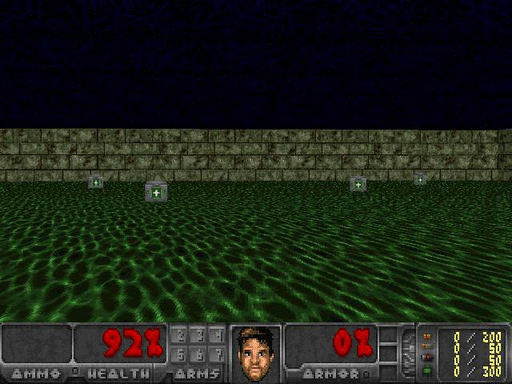
Figura 2. agentes aleatórios, Justin Francis fornecida
Vamos definir o ambiente de aprendizagem
aprendizado por reforço é considerado aprendizagem método de Monte Carlo Isto significa que o agente irá recolher os dados durante todo o processo de comportamento e contadas no fim do acto. No nosso exemplo, vamos coletar uma variedade de comportamentos para treiná-lo. Vamos colocar nossos dados de treinamento de ambiente é inicializado para esvaziar, em seguida, adicione gradualmente os nossos dados de treinamento.
Em seguida, definimos alguns dos parâmetros exceder o nosso processo de treinamento da rede neural será usado.
Alpha é a nossa taxa de aprendizagem, gama é a taxa de desconto recompensa. Recompensa de desconto é uma forma de avaliar possível recompensa futura no caso de uma determinada história agente recompensa. Se a taxa de desconto recompensa tende a 0, o agente só precisa se concentrar no prêmio atual sem a necessidade de considerar o futuro recompensa. Nós podemos escrever uma função simples para avaliar uma série de incentivos sob determinado comportamento, Aqui está o código:
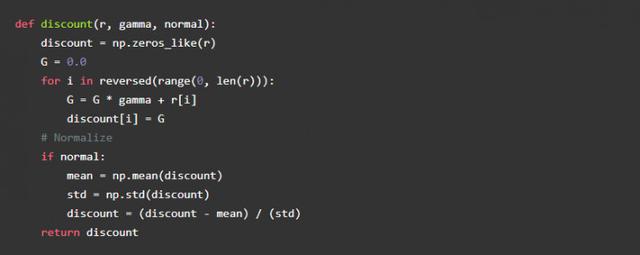
cálculo Recompensa:
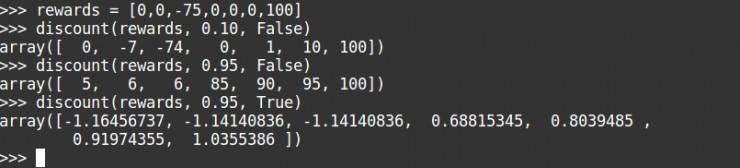
Você pode ver estes taxa de desconto alta, devido ao grande recompensa mais tarde, no meio de uma grande recompensa negativa foi ignorado. Podemos também acrescentar para formalizar nossos incentivos de desconto, para garantir que a nossa gama de incentivos para manter dentro de um determinado intervalo. Isto é muito importante na resolução do ambiente de desgraça.
Dado o valor do nosso estado continuará a funcionar, vamos sempre tentar se aproximar de um incentivo de desconto.
Estabelecer uma rede neural convolução
Em seguida, vamos construir um Estado recepção de rede neural convolucional, e, em seguida, emite os valores de estado correspondentes e a possibilidade de ação. Nós selecionamos três ações possíveis: para a frente, traseira esquerda e direita. A definições de política aproximados e imagem classificador é o mesmo, mas a diferença é de entrada é representado por uma classe de confiança, que irá representar a saída de uma confiança ação específica. Em contraste com o modelo de classificação de imagens de grandes dimensões utilizados para melhorar a aprendizagem, redes neurais simples será melhor.
Usaremos convnet, eo famoso algoritmo DQN usado anteriormente são semelhantes, entraremos uma imagem de rede tamanho de compressão neural 84X84 pixels, a saída de um 16-span de 4 de convolução 8X8 do kernel, seguido por 32 extensão convolução de 48X8 núcleo, com uma extremidade integralmente ligado neurónios 256 de nível. Para camada de convolução, vamos usar o VÁLIDO cheio, irá reduzir significativamente o tamanho da imagem.
Nossa estratégia e nosso valor aproximado da política, vai usar a mesma rede de convolução neural para calcular seu valor.
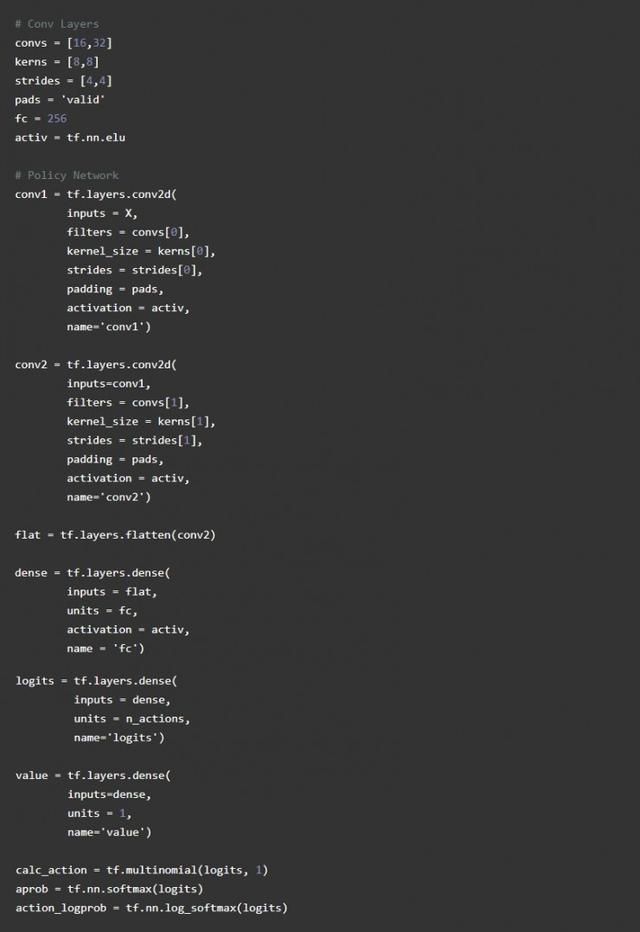
Em estudo aprofundado, a inicialização de peso é muito importante, tf.layers usados por glorot padrão intializer uniforme, que sabemos inicialização xavier para inicializar os pesos. Se você usar muito desvio para inicializar os pesos, então, agente será tendenciosa, se um muito pequenos desvios aleatórios de desempenho. A situação ideal é uma manifestação de um início aleatório, e então lentamente alterar o valor do peso de recompensas Maximizar. Em reforço de aprendizagem, que é conhecido como prospecção e exploração, porque quando o Agente inicial irá mostrar uma exploração aleatória do meio ambiente, em seguida, atualizar a cada um o seu comportamento provavelmente será capaz de obter uma boa recompensa lentamente em direção a ação para by.
E melhorar o desempenho computacional
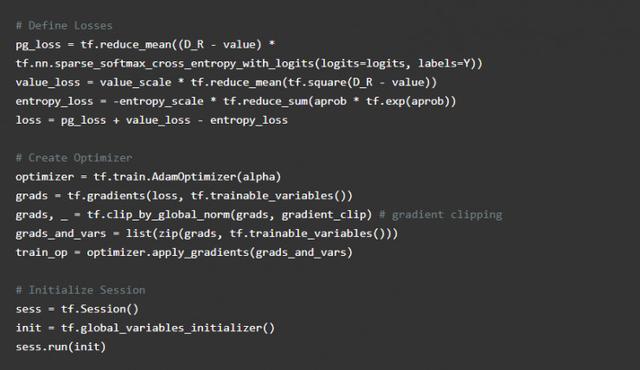
Agora nós estabelecemos um modelo, mas temos que começar a aprender como fazê-lo? A solução é simples. Queremos o direito de alterar a rede neural ação re-tomada para melhorar a nossa confiança, quanta mudança é baseada em como estimar com precisão a nossa base de valor. No geral, temos de minimizar nossas perdas.
Em TensorFlow alcançar o acima, foram calculadas as estratégias de perda que você pode usar a função sparse_softmax_cross_entropy. meios de etiquetas esparsas que o nosso comportamento é um único inteiro, e logits é a nossa última saída política inativo. Esta função calcula a softmax log e perda. Isso faz com que as ações realizadas confiança próximo de 1, a perda de perto de zero.
Então, vamos atravessar a perda de entropia multiplicado pelo desconto e recompensar nossos valores valor aproximado da diferença. Calculamos nossa perda no valor da utilização média perdas de erro comum. Então nós perdemos juntos para calcular a perda total.
Formação Agent
Agora estamos prontos para treinar o agente. Nós usamos o estado atual das entradas para a rede neural, recebe a ação, chamando a nossa função tf.multinomial, e, em seguida, especificar a ação e manter estado, ações e recompensas futuras. Nós armazenar o novo State2 como nosso estado atual, repita essa etapa até o final da cena. Em seguida, adicione os dados do estado, ação e recompensa a uma nova lista e vamos usar essas entradas para a rede para avaliar o lote.
De acordo com os nossos pesos iniciais de inicialização, o nosso agente deve, eventualmente, ser de cerca de 200 ciclos de treinamento para abordar ambiental, média 1.200 recompensa. solução OpenAI a este ambiente padrão é a capacidade de ganhar recompensas em 1000 de mais de 100 ensaios. Agente de permitir a formação contínua, pode atingir uma média de 1700, mas não parece bater esta média. Este é o meu agente após 1000 ciclo de formação:

Figura 3. 1.000 vezes, Justin Francis forneceu
A fim de melhor teste de confiança Agente em qualquer imagem Frame dado que você precisa para entrar no estado para a rede neural ea saída observado. Aqui, quando confrontados com uma parede, agente de 90% de confiança que a necessidade de tomar as medidas certas é a melhor, quando a próxima imagem no momento certo, Agente 61% de confiança para chegar à frente é o melhor ação.
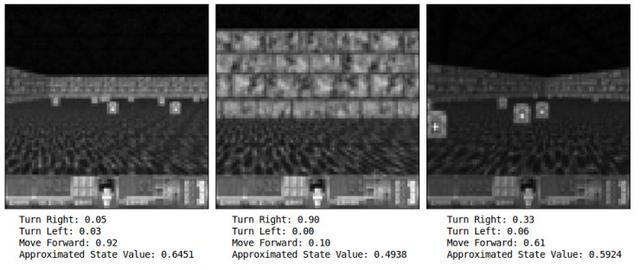
4. A FIG estado do comparador, Justin Francis fornecida
Pensar cuidadosamente sobre, você poderia pensar, 61% de confiança parece ser uma ação óbvia bom, isso não é tão bom, então você está em alta. Eu suspeito que o nosso agente em grande parte aprendido a evitar a parede, e porque o agente recebeu única recompensa sobreviver, não é especificamente tentando pegar kits médicos. Prontamente pegar kits médicos, fazendo um tempo de sobrevivência mais longa. De certa forma, eu não acho que isso é completamente inteligente Agent. Agente quase ignorando a virar à esquerda. Agente usou uma estratégia simples, ele teria sido auto-aprendizagem, bastante eficaz.
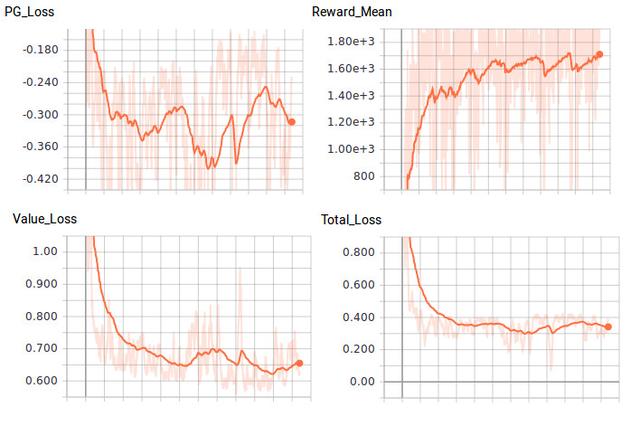
Figura 5. Comparação perdas e recompensa, Justin Francis fornecida
passo mais
Agora, eu espero que você entenda o básico do método de gradiente política. Melhor método Ator-Crítico, A3C ou PPO, que são a pedra angular da política para promover o progresso do método do gradiente. valores de erro reforçada modelo de transição de estado não considera, ou operação TD, também pode ser usado alocação de crédito problema. Para resolver estes problemas, mais e mais inteligente de dados de treinamento da rede neural. Há muitas maneiras de melhorar o desempenho, como ajustar os ultra-parâmetros. Com algumas pequenas modificações, você pode usar a mesma rede para resolver mais problemas Atari jogo. Para testá-lo, ver como ele funciona!
Lei Feng rede (nota do autor: Este artigo é Consulte a nossa declaração de colaboração independência editorial por O'Reilly e TensorFlow.)
Site: https: //www.oreilly.com/ideas/reinforcement-learning-with-tensorflow
