rede de Lei Feng: como aprendizado de máquina e inteligência artificial, apenas para descobrir tedioso duro no treino duro também para matar o tempo? Tubing canal arXiv Insights promoções semanais, a partir de uma perspectiva técnica, a profundidade de aprender com você facilmente.
acabamento de tradução / Zhao se gal / MY

Em configurações de reforço de aprendizagem, a fim de executar uma tarefa que queremos aprender, apreciar a aplicação inteligente de alguns dos programas de extração de características para extrair informações úteis a partir dos dados brutos, em seguida, haverá uma estratégia de rede para a extração de recursos.
Nós muitas vezes acham difícil de reforço de aprendizagem, ea razão pela qual se torna difícil é que nós usamos uma recompensa escassa. Agente necessidade de aprender com o feedback, e, em seguida, para distinguir que tipo de sequências de ação levará à recompensa final, mas na verdade o nosso sinal de feedback é escassa, de modo que o agente não pode extrair recursos úteis a partir dos dados brutos.
aprendizado por reforço atual em uma tendência dominante que a amplificação do sinal de recompensas externas esparsas derivados do meio jogo, e para ajudar o agente, aprendendo sinal de feedback adicional. Nós esperamos estabelecer um ambiente supervisionado e design é sinal de feedback adicional muito intenso, uma vez que o agente ter sucesso na tarefa, ele provavelmente terá conhecimento.
Este artigo pretende fornecer alguns dos estudos gerais existentes, vista direcional para todos através de alguns dos artigos descritos e analisados.
I. tarefas auxiliares
O primeiro ponto é tarefas auxiliares vai ajudar a treinar seu corpo inteligente simples superposição dessas metas, pode melhorar significativamente a eficiência de aprender nosso agente. Vamos olhar juntos um artigo do google deepmind, chamado reforço aprendizagem combinada com tarefa assistência aprendizado não supervisionado.

O artigo criou um labirinto em 3D, o agente no labirinto para caminhada, ele precisa encontrar um objeto específico, uma vez que encontra um desses objetos será recompensado. Os autores substituir estes recompensa muito escassa, e com três sinal de bônus para amplificar todo o processo de formação.
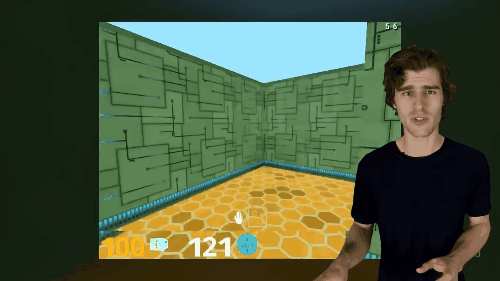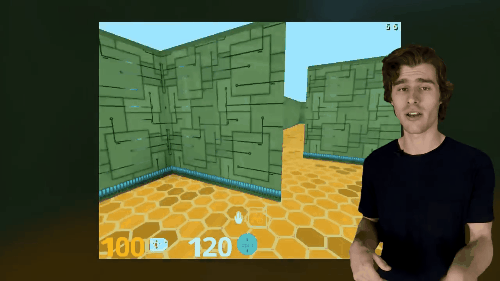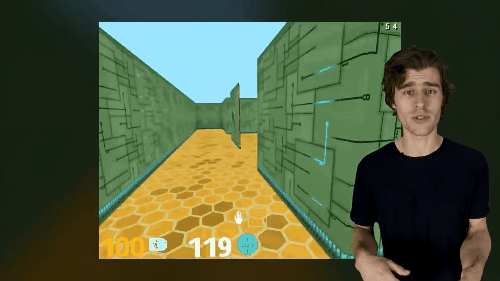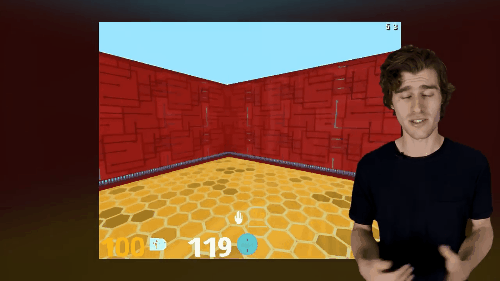
A primeira tarefa é controlar os pixels. valores de pixel agente precisa aprender uma estratégia separada para maximizar alterar algumas partes da imagem de entrada, quadro entrou na implementação das suas recomendações são divididos em um pequeno número de grades, cada grade de computação uma mudança visual na pontuação, então a política eles foram treinados para maximizar os totais mudanças visuais tudo grid. Junte-se a tarefas de controle de pixel em um ambiente tridimensional é muito eficaz.
A segunda tarefa é a de auxiliar a predição recompensa. Agente é administrado numa sequência fragmento (sequência episódio) nos mais recentes três quadros, a sua tarefa é de prever o próximo passo será dado incentivos.
A terceira tarefa é a reprodução função de avaliação. Por previsão, o agente receberá a soma de recompensas futuras, neste momento em diante.
exploração II. curiosidade-driven
O segundo ponto é a exploração movida pela curiosidade, a visão popular é que você quer de alguma forma premiar o seu agente, depois que ele aprendeu uma coisa nova para explorar o ambiente após a descoberta.
Na maioria aprendizado por reforço algoritmo padrão, as pessoas vão usar para explorar métodos e- ganancioso, que na maioria dos casos sua experiência inteligente sob sua política existente mais propensos a escolher a melhor direção, pequena probabilidade de agente no caso irá executar uma ação aleatória, e com o progresso do treinamento, o movimento aleatório será gradualmente reduzido até que cumpra plenamente com a sua decisão. É também por isso, seu corpo pode não ser inteligente para procurar uma estratégia melhor e explorar plenamente o ambiente inteiro.
Em reforço de aprendizagem, vamos recordar um modelo para a frente, o que significa que seu agente vai ver quadros de entrada específico, ele vai usar algum tipo de recurso exaustor e os dados de entrada para codificar a alguma representação oculta, então você tem um modelo para a frente. Se for uma nova posição, modelo frente agente pode não ser tão preciso, você pode usar estes erro de previsão como um sinal de feedback adicional além dos incentivos esparsas para incentivar o seu agente para explorar a área de espaço estado desconhecido .

Agora eu gostaria de introduzir um artigo, os autores utilizaram um bom exemplo para demonstrar o módulo curiosidade intrínseca (ICM).
Todos nós sabemos que é muito difícil de modelar a brisa, e muito menos prever cada peça de folhas mudam de pixel. movimento folhas não pode ser controlado agente de ação, pois as características do codificador há incentivo para aqueles para orientar deixa a modelagem, o que significa que o erro de predição do espaço de pixel teria sido elevado, o agente terá em folhas manteve um curioso, este é o modelo ICM arquitetura tese.

O estado original do ambiente, S, S + 1 no espaço de características é primeiro codificado, seguido por dois modelos: um é um modelo para a frente, este modelo, a fim de prever o próximo estado é caracterizado pela estratégia de operação escolhido, então há uma trans modelo de transferência de prever quais ações devem ser escolhidos para + 1 de estado s para características de um próximo estado s. A última codificação recurso e s + 1 dado por + 1 características de codificação preditiva do modelo frente s são comparadas, a comparação dos resultados, podemos chamar o grau de agente de surpresa do que aconteceu, e é adicionado ao sinal, a fim de recompensa agente de formação.
Este é um bom ponto de vista, o nosso agente deve ser para explorar a região desconhecida e a curiosidade mundo.
III. Definindo a recompensa padrão
O terceiro ponto de vista de incentivos configuração padrão para que fragmentos do agente nunca conseguem aprendizagem. Podemos ver o AI aberta publicou recentemente um artigo chamado após a experiência de reprodução, ou abreviaturas ela.

Imagine que você quer treinar um robô para empurrar um objeto sobre a mesa para alcançar a posição A, mas devido à política não são bem treinados, no final do objeto B, segundo o ponto de vista objectivo é a tentativa mal sucedida, e seus modelos não basta dizer " Ei! você errou, você tem um valor de 0 bônus "mas disse o agente," awesome! bem feito, isto é como você mover um objeto para a posição B", você tem basicamente uma escassa recompensa a questão estabeleceu um conjunto muito denso de incentivos para tornar agente de aprendizagem.
Temos um comum off-line de aprendizagem algoritmo e amostragem estratégia para o local de destino para o começo, mas então também provar um número de alvos adicionais para ser alterado. Este algoritmo é a melhor coisa depois do treino você já tem uma rede política, por isso, se você deseja mover um objeto para um novo local, você não precisa re-treinar todas as políticas, só precisa mudar o vector alvo, sua estratégia vai fazer a coisa certa. ponto de vista do papel é muito simples, mas para resolver uma questão muito básica de nosso aprendizado, que queremos maximizar o uso de alguns dos nossos cada experiência.

Nós apenas partilhada algumas maneiras muito diferentes para aumentar o sinal de recompensa é escassa, através de feedback intensiva Eu acho que o primeiro passo tende a ser verdade de aprendizado não supervisionado. Mas em aprendizado por reforço ainda há muitas questões desafiadoras, como o estudo da migração generalização, a causalidade em física e assim por diante, esses problemas ainda existem como um desafio. Ao mesmo tempo, a nossa relação também precisa de um melhor equilíbrio no desenvolvimento da inteligência artificial e do desenvolvimento social e criar um todos possam beneficiar o desenvolvimento da inteligência artificial no negócio.
Link do vídeo: https: //www.youtube.com/watch v = 0Ey02HT_1Ho & t = 364S?
Lei Feng Lei Feng net net